

Visual Elevator Music
How AI systems converge, and why this has happened before

One through six. That was the scale. Muzak Corporation rated every arrangement in its catalog on a proprietary index called the Stimulus Code, and what the index measured was blandness. A one: soft strings, harmonic wallpaper. A six: enough forward motion that your body might register a tempo. The upper bound of what the system could tolerate before the music risked becoming music. The production was a feature-removal pipeline. Fifty arrangers recorded entirely new versions of existing compositions, stripping vocals (conscious attention was the enemy of the product), heavy bass, anything a listener might register. Themes were disguised with counterpoint and flute flutter. Queen’s “Another One Bites the Dust” was rejected as “choral speech with rhythm,” irreducible to the format. An executive put the design principle plainly: “Once people start listening, they stop working.” The rated arrangements fed a scheduling system called Stimulus Progression: fifteen-minute blocks of ascending energy, the most stimulating segments timed to 10:30 a.m. and 3:00 p.m. to counteract the body’s natural fatigue dips. A Stanford industrial psychologist called it aligning music’s frequency with metabolic rhythms. The science was dubious. The system was not. By the late 1990s the company piped its signal by satellite to over 300,000 locations across nineteen countries on non-cancelable five-year contracts at forty-five dollars a month, a hundred million ears daily. The person hearing the music was not the customer. The customer was the office manager, the retail chain, buyers optimizing for productivity per square foot. The listener had no feedback mechanism and no off switch.
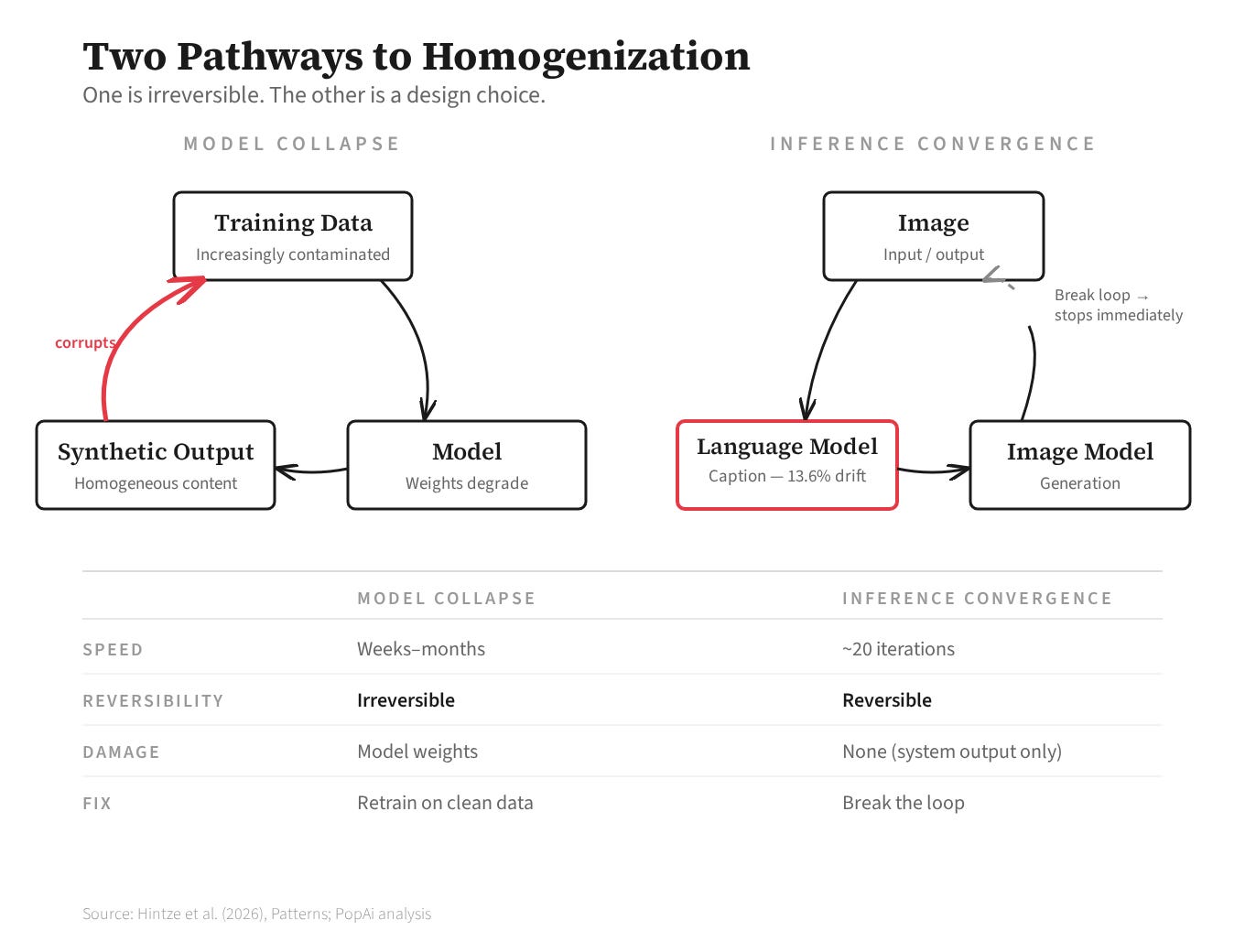
That production logic — take distinctive input, strip distinctiveness, calibrate the residue to the buyer’s metric, distribute at scale — ran for seven decades. In January 2026, a study published in Patterns showed that two AI models, looping through each other’s outputs, converge to the same endpoint in about twenty iterations.1
Seven hundred starting points. Sixteen model-pair combinations. Twelve images they all settle on: stormy lighthouses, Gothic cathedrals, rainy European streets, pastoral landscapes, palatial interiors. The researchers called what emerged “visual elevator music.” (The complete dataset is open access.)
Each cycle, a language model describes an image and an image model reconstructs it. The description is a compression: it keeps what’s salient and discards what’s specific. The angle of light, the texture of stone, the spatial relationship that made this particular image particular — lost in the description, replaced by the statistical center of the training data. Iterate, and the specifics regress toward the mean. The variance analysis locates the bottleneck: captioning models account for 13.6% of the semantic drift between iterations, significant at p < 10⁻¹⁹. Image generators contribute 0.2%, statistically indistinguishable from zero. Language is the compression step. The image model faithfully renders whatever it’s told; the language model decides what’s worth telling. And what’s worth telling, cycle after cycle, is whatever is most easily described, which is whatever is most common in the data the language model was trained on.2
Griffiths and Kalish showed in 2007 that when agents iteratively learn from each other’s outputs through any channel that compresses the signal, the system converges to its prior distribution. Repeated lossy transmission doesn’t produce drift. It produces regression to whatever distribution the system started with. Here, the prior is internet-scale image-text corpora — the statistical summary of what the web considers normal. Each inference pass is a Bayesian update that pulls the output back toward that summary.3
The obvious objection is to turn up the randomness. Hintze’s team tested seven temperature settings across all 700 trajectories. Every temperature converged to the same twelve motifs. Higher temperatures produce noisier paths but identical endpoints. The attractors are temperature-invariant. Sixteen model-pair combinations, all converge — the Platonic Representation Hypothesis explains why: as models scale and train on overlapping data, their internal representations approach the same statistical model of reality regardless of architecture.4 The attractors are properties of the shared data, not of any one model’s configuration. And this is not model collapse. Model collapse requires retraining on synthetic output; it corrupts the model’s weights and is irreversible. Inference-loop convergence is different. No retraining occurs. The models are frozen. Convergence emerges purely from repeated translation between modalities and stops the moment you break the loop. Twenty iterations to convergence, zero to recovery. The models aren’t damaged. They’re doing what their architecture dictates when left to iterate without external input, which means convergence is a design choice that can be made differently.
At the consumer level, audiences are filtering AI content out. AI-generated music captures less than half a percent of organic streams. Art collectors report a 2% AI purchase rate. If convergence only mattered when it reached people directly, it would be a problem for stock libraries, not for culture.
Three studies, published independently across different disciplines, show why it matters anyway.
Agarwal and colleagues found that participants from diverse cultural backgrounds, using AI writing suggestions, produced output that homogenized toward Western stylistic norms. The participants believed they were making independent creative choices. Lee and Hosanagar ran a randomized controlled trial across 82,290 products and 1.1 million users: each user discovered more varied products, but overall diversity decreased. The system pushed every user toward a broader range — the same broader range. Doshi and Hauser, in Science Advances, found that AI-assisted creative writing produced stories rated as more creative individually but more similar to each other collectively.5
Creation, recommendation, collaborative writing. Different domains, different years, different methodologies. The person inside the system experiences improvement while the aggregate distribution contracts. The convergence is invisible from inside the loop. What the Hintze study documents with two AI systems translating through a lossy bottleneck, these three studies document with a human performing the compression step — accepting a suggestion that pulls toward the training distribution’s center, following a recommendation that concentrates aggregate attention. The bottleneck is still language. The compression is still lossy. The person doing the compressing doesn’t notice.
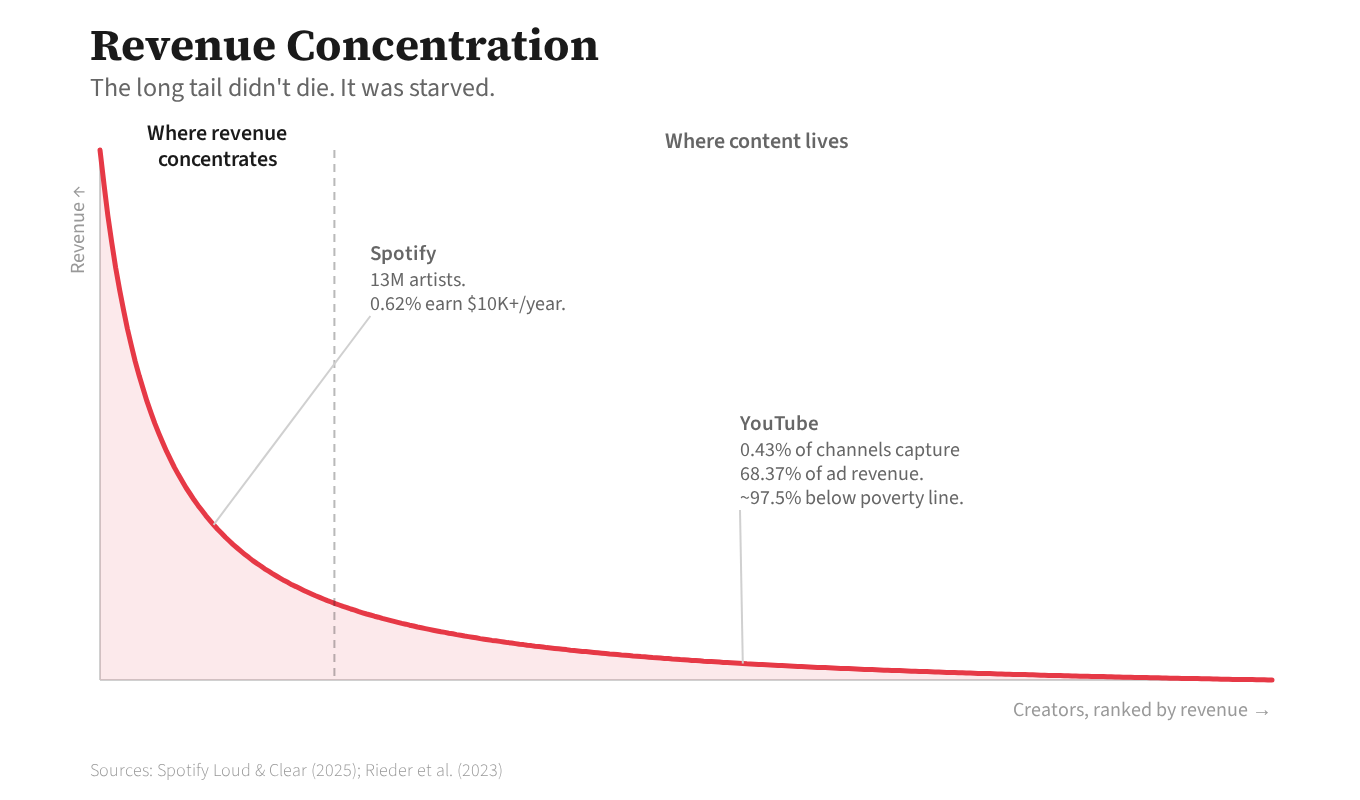
Spotify hosts thirteen million artists; 0.62% generate more than ten thousand dollars a year. This is the ecosystem AI convergence enters, and the marketplace rewards what convergence produces: content that clusters near the statistical mean.
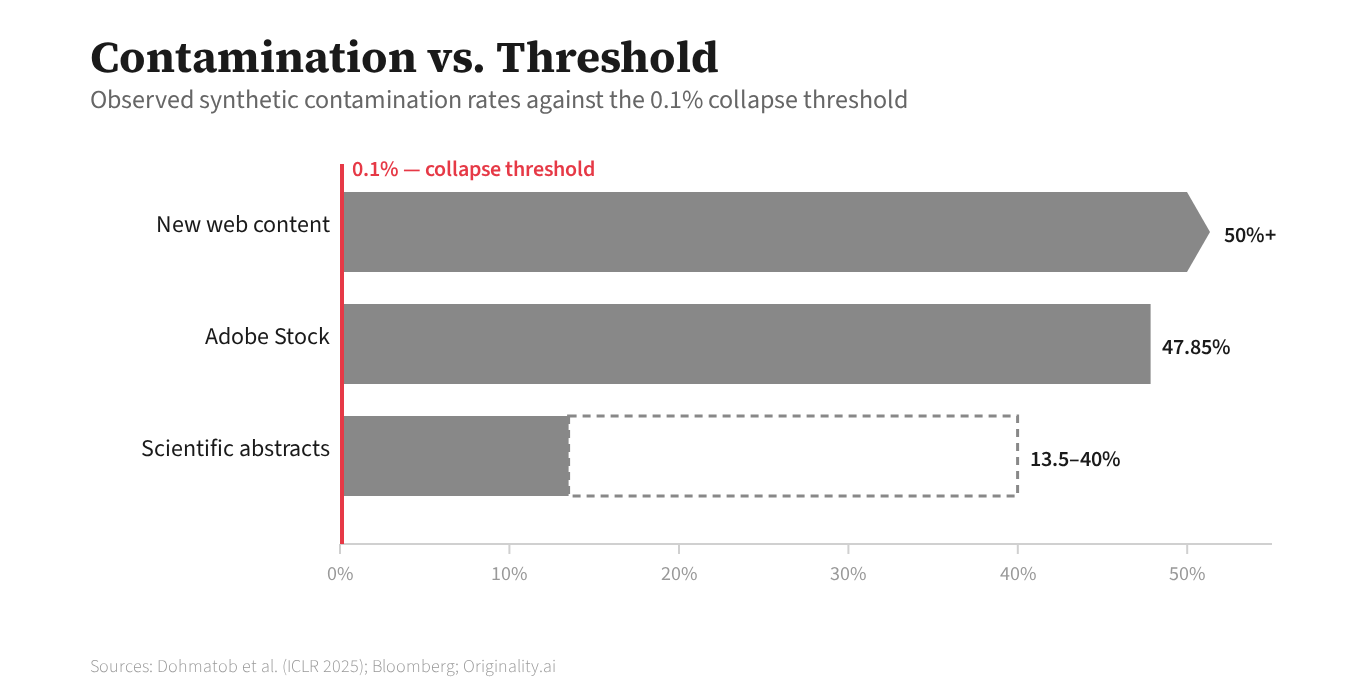
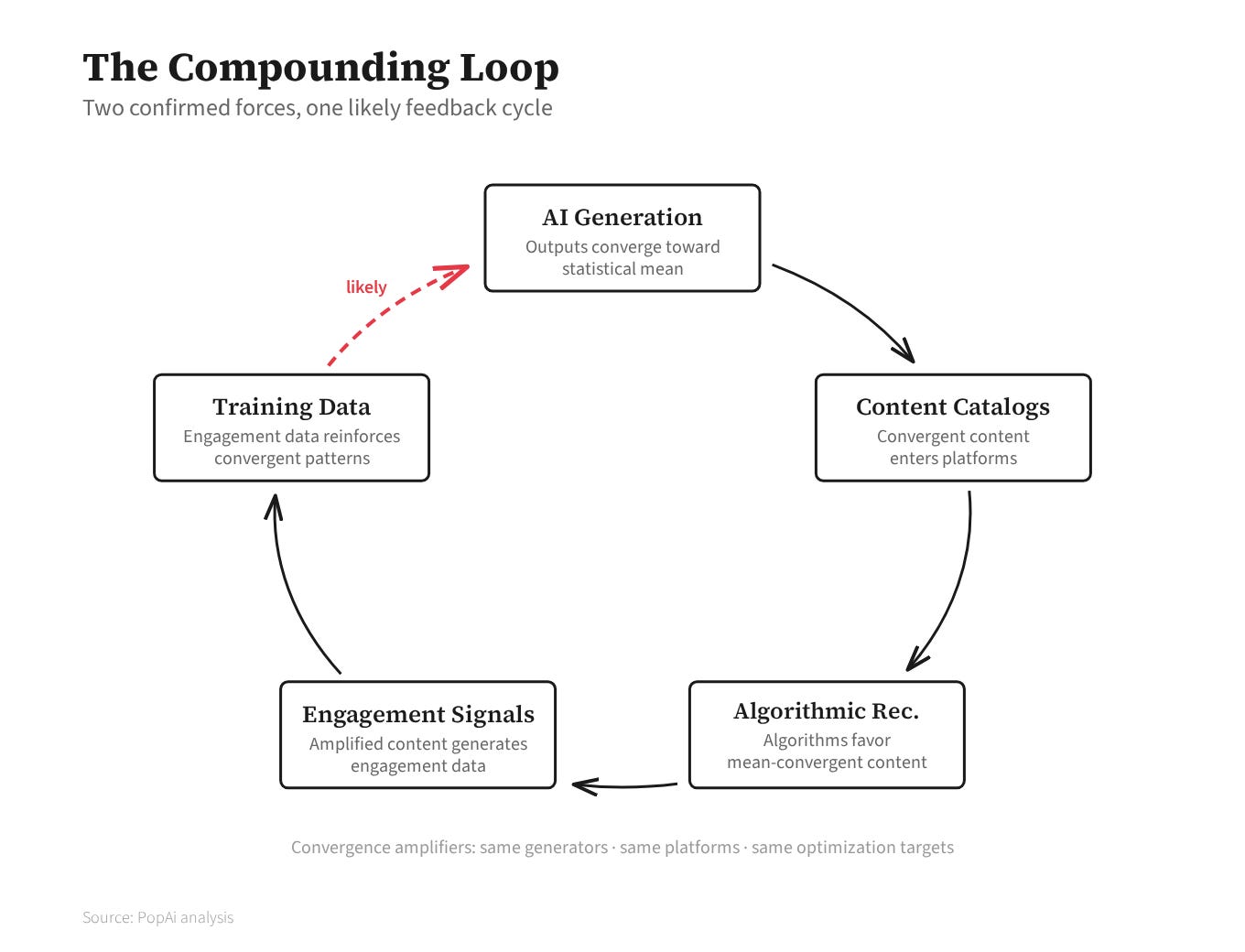
Adobe Stock is the clearest closed loop: 48% AI-generated, Firefly trained on stock content that includes AI images, generation feeding the corpus that feeds training.6 The compounding hypothesis, with each link graded by evidence. AI outputs converge toward the statistical mean. Confirmed: the Hintze study, the Doshi and Hauser experiments, the model-collapse research. Recommendation algorithms preferentially surface mean-convergent content. Confirmed: Klimashevskaia and colleagues surveyed 123 papers on popularity bias and found the problem persists across every modern architecture. These two forces form a self-reinforcing cycle. Likely: each component is independently established; the full loop has not been tested end to end.7
The convergence compounds through a triple monoculture: every major platform migrating to transformer-based recommendation, all optimizing for engagement variants, AI generators trained on the same distributions those algorithms reward. The long tail doesn’t die by replacement. It dies by starvation — the content exists, more of it than ever, but it doesn’t reach anyone. Less engagement data means lower surfacing probability means less engagement data. The spiral has no natural floor.
The interventions exist, and they produce results. Quality-diversity algorithms don’t generate output and hope for variety; they optimize for diversity explicitly. Google DeepMind’s AlphaEvolve used quality-diversity search to discover matrix multiplication algorithms that broke a fifty-six-year mathematical bound; Meta’s Rainbow Teaming scaled the approach to production safety testing. If you don’t build diversity into the objective function, you don’t get it in the output.8 Distributed selection preserves what centralized selection destroys. Epstein and colleagues ran a randomized controlled trial with over ten thousand participants: diverse local communities selecting independently maintained aesthetic variety; centralized preference training through RLHF collapsed it. The architecture of who chooses matters more than whether humans are in the loop. Human curation can amplify convergence or resist it, depending entirely on how it’s organized.9 And when optimization is constrained by external reality rather than by the statistical echo of prior outputs, genuine novelty emerges. AlphaGo found moves no human professional would play, because the system optimized against the physics of the game board rather than against the distribution of historical play. Protein design produces molecules verified by X-ray crystallography, not by resemblance to known proteins.10
The interventions are validated. Most deployed systems don’t implement them, because homogeneity is cheaper and better aligned with engagement metrics that treat the mean as the target.
Three diagnostic questions for the next AI system or recommendation feed you encounter. Is this system iterating on its own outputs? The Hintze study showed twenty iterations to convergence. Adobe Stock has already closed the loop at commercial scale. If the feedback path exists and nobody is breaking it, the system is converging. Who benefits from the output — the person experiencing it, or someone else? Muzak sold to office managers, not to the workers hearing the music. When the buyer’s metric diverges from the audience’s experience, homogenization is a feature, not a failure. Is diversity being maintained deliberately, or assumed to happen on its own? Temperature doesn’t help. Model diversity doesn’t help. If nobody is engineering for diversity, nobody is getting it.
Muzak’s Stimulus Code was a diagnostic instrument — a scale for measuring the blandness of a system designed to produce blandness. Seventy years later, we have systems converging toward their own visual elevator music, operating through pipelines and recommendation architectures that feel helpful from the inside, and no equivalent instrument for seeing it happen. The tools to build one exist. Whether anyone builds it is a question about economics, not engineering.
This piece compressed a lot. The variance analysis, the iterated learning theory, the economics of long-tail starvation, the intervention architectures — each could be its own essay. If any of those threads are worth pulling on for you, I'd like to hear about it. Reply to this email or find me at thbrdy.dev.
[1]: Hintze, A., Proschinger Åström, F., & Schossau, J. (2026). Visual elevator music: AI-to-AI loops converge to generic imagery. Patterns, Cell Press. Complete dataset: figshare (CC BY 4.0).
[2]: Variance analysis from the Hintze study. The 13.6% figure reflects the proportion of semantic drift attributable to captioning models across all trajectories. The captioning bottleneck is consistent across all sixteen model-pair combinations tested.
[3]: Griffiths, T. L., & Kalish, M. L. (2007). Language evolution by iterated learning with Bayesian agents. Cognitive Science, 31(3), 441–480. The proof was established for iterated human learning and simple generative models. Its application to frozen multimodal AI loops is strongly supported by the experimental evidence but has not been formally proven for this specific case. The researchers themselves frame the dynamics in terms of attractor convergence rather than formally invoking Griffiths-Kalish; the theoretical mapping is editorially proposed.
[4]: Huh, M., et al. (2024). The Platonic Representation Hypothesis. Preprint. Temperature-invariance data from the Hintze study: seven settings from 0.1 to 1.3, pooled k-means clustering yielding 12 clusters across all temperatures.
[5]: Agarwal, S., et al. Cross-cultural study of AI writing suggestions and output homogenization. Lee, D., & Hosanagar, K. (2017). How do recommender systems affect sales diversity? Randomized field experiment, 82,290 SKUs, 1.1M users. Doshi, A. R., & Hauser, O. (2024). Generative AI enhances individual creativity but reduces the collective diversity of novel content. Science Advances.
[6]: Adobe Stock figures from Bloomberg investigation. Firefly training data composition from Adobe’s public disclosures. Dohmatob et al. (ICLR 2025) proved that 0.1% synthetic contamination triggers measurable model collapse. Adobe Stock sits three orders of magnitude past that threshold.
[7]: Klimashevskaia, A., et al. (2024). Survey of popularity bias in recommendation systems. User Modeling and User-Adapted Interaction. Evidence grading: CONFIRMED indicates peer-reviewed, replicated findings; LIKELY indicates mechanistically sound claims not yet tested as unified phenomena. Kleinberg, J., & Raghavan, M. (2021). Algorithmic monoculture and social welfare. PNAS.
[8]: AlphaEvolve matrix multiplication results from Google DeepMind (2025). Rainbow Teaming from Samvelyan et al. (2024), deployed in Meta’s production safety pipeline.
[9]: Epstein, Z., et al. Randomized controlled trial, 10,000+ participants. The finding that distributed selection maintains diversity while centralized RLHF/DPO destroys it holds across multiple aesthetic domains tested.
[10]: The external-grounding hypothesis — that constrained optimization with verification resists convergence while open-ended aesthetic generation doesn’t — is editorially proposed as a framework. De novo protein design references Dauparas et al. and related work in computationally designed proteins verified by experimental structure determination.